/* per device-cgroup pair */ structioc_gq { structblkg_policy_datapd; structioc *ioc;
/* * A iocg can get its weight from two sources - an explicit * per-device-cgroup configuration or the default weight of the * cgroup. `cfg_weight` is the explicit per-device-cgroup * configuration. `weight` is the effective considering both * sources. * * When an idle cgroup becomes active its `active` goes from 0 to * `weight`. `inuse` is the surplus adjusted active weight. * `active` and `inuse` are used to calculate `hweight_active` and * `hweight_inuse`. * * `last_inuse` remembers `inuse` while an iocg is idle to persist * surplus adjustments. * * `inuse` may be adjusted dynamically during period. `saved_*` are used * to determine and track adjustments. */ u32 cfg_weight; u32 weight; u32 active; u32 inuse;
u32 last_inuse; s64 saved_margin;
sector_t cursor; /* to detect randio */
/* * `vtime` is this iocg's vtime cursor which progresses as IOs are * issued. If lagging behind device vtime, the delta represents * the currently available IO budget. If running ahead, the * overage. * * `vtime_done` is the same but progressed on completion rather * than issue. The delta behind `vtime` represents the cost of * currently in-flight IOs. */ atomic64_t vtime; atomic64_t done_vtime; u64 abs_vdebt;
/* current delay in effect and when it started */ u64 delay; u64 delay_at;
/* * The period this iocg was last active in. Used for deactivation * and invalidating `vtime`. */ atomic64_t active_period; structlist_headactive_list;
/* see __propagate_weights() and current_hweight() for details */ u64 child_active_sum; u64 child_inuse_sum; u64 child_adjusted_sum; int hweight_gen; u32 hweight_active; u32 hweight_inuse; u32 hweight_donating; u32 hweight_after_donation;
Comprehensive quick reference guide for Linux networking data structures, kernel functions, system calls, and debugging commands. Essential resource for network developers and system administrators.
Master essential Linux networking tools and scripts for debugging, performance testing, and network analysis. Learn packet tracing, comprehensive debugging, and systematic performance evaluation.
Explore cutting-edge Linux networking features including eBPF programming, XDP high-performance packet processing, and advanced optimization techniques for maximum network performance.
Complete guide to Linux kernel networking - from hardware interrupts to application delivery. Learn packet flow, debugging techniques, and performance optimization.
Values related to processor utilization are displayed on the third line. They provide insight into exactly what the CPUs are doing.
us is the percent of time spent running user processes.
sy is the percent of time spent running the kernel.
ni is the percent of time spent running processes with manually configured nice values.
id is the percent of time idle (if high, CPU may be overworked).
wa is the percent of wait time (if high, CPU is waiting for I/O access).
hi is the percent of time managing hardware interrupts.
si is the percent of time managing software interrupts.
st is the percent of virtual CPU time waiting for access to physical CPU.
In the context of the top command in Unix-like operating systems, the “wa” field represents the percentage of time the CPU spends waiting for I/O operations to complete. Specifically, it stands for “waiting for I/O.”
The calculation includes the time the CPU is idle while waiting for data to be read from or written to storage devices such as hard drives or SSDs. High values in the “wa” field may indicate that the system is spending a significant amount of time waiting for I/O operations to complete, which could be a bottleneck if not addressed.
The formula for calculating the “wa” value is as follows:
wa %=(Time spent waiting for I/O / Total CPU time)×100
Also we can use vmstat 1 to watch the wa state in system, but it is the not the percent:
Procs r: The number of processes waiting for run time. b: The number of processes in uninterruptible sleep. Memory swpd: the amount of virtual memory used. free: the amount of idle memory. buff: the amount of memory used as buffers. cache: the amount of memory used as cache. inact: the amount of inactive memory. (-a option) active: the amount of active memory. (-a option) Swap si: Amount of memory swapped in from disk (/s). so: Amount of memory swapped to disk (/s). IO bi: Blocks received from a block device (blocks/s). bo: Blocks sent to a block device (blocks/s). System in: The number of interrupts per second, including the clock. cs: The number of context switches per second. CPU These are percentages of total CPU time. us: Time spent running non-kernel code. (user time, including nice time) sy: Time spent running kernel code. (system time) id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time. wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle. st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
In summary, a high “wa” value in the output of top suggests that your system is spending a considerable amount of time waiting for I/O operations to be completed, which could impact overall system performance. Investigating and optimizing disk I/O can be beneficial in such cases, possibly by improving disk performance, optimizing file systems, or identifying and addressing specific I/O-intensive processes. We can use iotop to find the high io or slow io processes in system:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Current DISK READ: 341.78 M/s | Current DISK WRITE: 340.53 M/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 3487445 be/4 root 34.44 M/s 33.36 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487446 be/4 root 33.40 M/s 34.27 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487447 be/4 root 34.10 M/s 33.78 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487448 be/4 root 32.21 M/s 31.64 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487449 be/4 root 34.22 M/s 34.44 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487450 be/4 root 34.46 M/s 34.33 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487451 be/4 root 34.17 M/s 34.21 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487452 be/4 root 33.05 M/s 32.95 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487453 be/4 root 34.23 M/s 34.74 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 3487454 be/4 root 37.51 M/s 36.79 M/s ?unavailable? fio -filename=/mnt/hostroot/var/mnt/testfile -direct=1 -iodepth 64 -thread -rw=randrw -ioengine=libaio -bs=8k -size=20G -numjobs=10 -group_reporting --runtime=100 -name=mytest 1 be/4 root 0.00 B/s 0.00 B/s ?unavailable? systemd --switched-root --system --deserialize 29 2 be/4 root 0.00 B/s 0.00 B/s ?unavailable? [kthreadd] 3 be/4 root 0.00 B/s 0.00 B/s ?unavailable? [rcu_gp] 4 be/4 root 0.00 B/s 0.00 B/s ?unavailable? [rcu_par_gp] 6 be/4 root 0.00 B/s 0.00 B/s ?unavailable? [kworker/0:0H-events_highpri]
Code tracing
From strace the top command, the wa value is get the status from /proc/*/stat. The /proc/*/stat is wrote by the proc ops and get the iowait time from kernel_cpustat.cpustat[CPUTIME_IOWAIT] accroding to the code fs/proc/stat.c.
if (cpu_online(cpu)) iowait_usecs = get_cpu_iowait_time_us(cpu, NULL);
if (iowait_usecs == -1ULL) /* !NO_HZ or cpu offline so we can rely on cpustat.iowait */ iowait = kcs->cpustat[CPUTIME_IOWAIT]; else iowait = iowait_usecs * NSEC_PER_USEC;
return iowait; }
In the Linux kernel, the calculation of the “wa” (waiting for I/O) value that is reported by tools like top is handled within the kernel’s scheduler. The specific code responsible for updating the CPU usage statistics can be found in the kernel/sched/cputime.c file.
One of the key functions related to this is account_idle_time().
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* * Account for idle time. * @cputime: the CPU time spent in idle wait */ voidaccount_idle_time(u64 cputime) { u64 *cpustat = kcpustat_this_cpu->cpustat; structrq *rq = this_rq();
u32 nr_iowait; /* number of blocked threads (waiting for I/O) */
This function is part of the kernel’s scheduler and is responsible for updating the various CPU time statistics, including the time spent waiting for I/O. The function takes into account different CPU states, such as idle time and time spent waiting for I/O.When The blocked threads with waiting for I/O, the cpu time accumulated into CPUTIME_IOWAIT.
Here is a basic outline of how the “wa” time is accounted for in the Linux kernel:
Idle time accounting: The kernel keeps track of the time the CPU spends in an idle state, waiting for tasks to execute.
I/O wait time accounting: When a process is waiting for I/O operations (such as reading or writing to a disk), the kernel accounts for this time in the appropriate CPU state, including the “wa” time.
# block/blk-core.c voidblk_io_schedule(void) { /* Prevent hang_check timer from firing at us during very long I/O */ unsignedlong timeout = sysctl_hung_task_timeout_secs * HZ / 2; if (timeout) io_schedule_timeout(timeout); else io_schedule(); } EXPORT_SYMBOL_GPL(blk_io_schedule);
# kernel/sched/core.c /* * This task is about to go to sleep on IO. Increment rq->nr_iowait so * that process accounting knows that this is a task in IO wait state. */ long __sched io_schedule_timeout(long timeout) { int token; long ret;
token = io_schedule_prepare(); ret = schedule_timeout(timeout); io_schedule_finish(token);
return ret; } EXPORT_SYMBOL(io_schedule_timeout);
intio_schedule_prepare(void) { int old_iowait = current->in_iowait;
switch (timeout) { case MAX_SCHEDULE_TIMEOUT: /* * These two special cases are useful to be comfortable * in the caller. Nothing more. We could take * MAX_SCHEDULE_TIMEOUT from one of the negative value * but I' d like to return a valid offset (>=0) to allow * the caller to do everything it want with the retval. */ schedule(); goto out; ... } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
staticint try_to_wake_up(struct task_struct *p, unsignedint state, int wake_flags) { ... if (task_cpu(p) != cpu) { if (p->in_iowait) { delayacct_blkio_end(p); atomic_dec(&task_rq(p)->nr_iowait); }
Investigate the blktrace implementation to understand the trace hook of the blk IO stack?
blktrace to parse the block io
blktrace explores the Linux kernel tracepoint infrastructure to track requests in-flight through the block I/O stack. It traces everything that goes through to block devices, while observing timing information.
First we using dd command to make a write IO (the read IO is the same).
1 2 3 4 5
// write to a file with direct io by dd command # ddif=/dev/zero of=testfile bs=16k count=1024000 oflag=direct 1024000+0 records in 1024000+0 records out 16777216000 bytes (17 GB, 16 GiB) copied, 111.433 s, 151 MB/s
The following table shows the various actions which may be output:
A IO was remapped to a different device
B IO bounced
C IO completion
D IO issued to driver
F IO front merged with request on queue
G Get request
I IO inserted onto request queue
M IO back merged with request on queue
P Plug request
Q IO handled by request queue code
S Sleep request
T Unplug due to timeout
U Unplug request
X Split
The result is long and there only paste few of them. I try to trace an different sectors and behaviors of block layer.
blkparse command still hard to know the total metrics and statistics, so we can use btt to see the statistic of whole table and picture, this is the part of results:
Q------->G------------>I--------->M------------------->D----------------------------->C |-Q time-|-Insert time-| |--------- merge time ------------|-merge with other IO| |----------------scheduler time time-------------------|---driver,adapter,storagetime--|
|----------------------- await time in iostat output ----------------------------------|
Q2Q — time between requests sent to the block layer
Q2G — time from a block I/O is queued to the time it gets a request allocated for it
G2I — time from a request is allocated to the time it is inserted into the device’s queue
Q2M — time from a block I/O is queued to the time it gets merged with an existing request
I2D — time from a request is inserted into the device’s queue to the time it is actually issued to the device (time the I/O is “idle” on the request queue)
M2D — time from a block I/O is merged with an exiting request until the request is issued to the device
D2C — service time of the request by the device (time the I/O is “active” in the driver and on the device)
Q2C — total time spent in the block layer for a request
Actually the blktrace’s implement is using various linux kernel tracepoint to trace different phase of IO. Here are some of the key tracepoints used by blktrace:
block_rq_insert: This tracepoint is hit when a request is inserted into the request queue.(Q)
block_rq_issue: This tracepoint is hit when a request is issued to the device.(I)
block_rq_complete: This tracepoint is hit when a request is completed.(C)
block_bio_queue: This tracepoint is hit when a bio is queued.(Q)
block_bio_backmerge: This tracepoint is hit when a bio is being merged with the last bio in the request.
block_bio_frontmerge: This tracepoint is hit when a bio is being merged with the first bio in the request.
block_bio_bounce: This tracepoint is hit when a bio is bounced.
block_getrq: This tracepoint is hit when get_request() is called to allocate a request.
block_sleeprq: This tracepoint is hit when a process is going to sleep waiting for a request to be available.
block_plug: This tracepoint is hit when a plug is inserted into the request queue.
block_unplug: This tracepoint is hit when a plug is removed from the request queue.
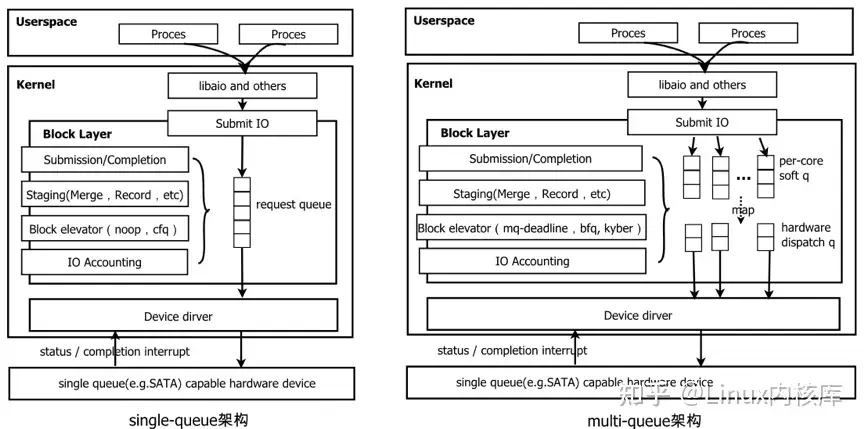
Main data structure in block layer
To deepdiv the block layer, i read the code and finding as followes:
/* * main unit of I/O for the block layer and lower layers (ie drivers and * stacking drivers) */ structbio { structbio *bi_next;/* request queue link */ structblock_device *bi_bdev; unsignedlong bi_rw; /* read or write */ ... structbio_vec *bi_io_vec;/* the actual vec list */ structbvec_iterbi_iter;
};
/** * struct bio_vec - a contiguous range of physical memory addresses * @bv_page: First page associated with the address range. * @bv_len: Number of bytes in the address range. * @bv_offset: Start of the address range relative to the start of @bv_page. * * The following holds for a bvec if n * PAGE_SIZE < bv_offset + bv_len: * * nth_page(@bv_page, n) == @bv_page + n * * This holds because page_is_mergeable() checks the above property. */ structbio_vec { structpage *bv_page; unsignedint bv_len; unsignedint bv_offset; };
/* * Try to put the fields that are referenced together in the same cacheline. * * If you modify this structure, make sure to update blk_rq_init() and * especially blk_mq_rq_ctx_init() to take care of the added fields. */ structrequest { structrequest_queue *q; structbio *bio; structbio *biotail; union { structlist_headqueuelist; structrequest *rq_next; }; enummq_rq_statestate; /* * The hash is used inside the scheduler, and killed once the * request reaches the dispatch list. The ipi_list is only used * to queue the request for softirq completion, which is long * after the request has been unhashed (and even removed from * the dispatch list). */ union { structhlist_nodehash;/* merge hash */ structllist_nodeipi_list; };
/* * The rb_node is only used inside the io scheduler, requests * are pruned when moved to the dispatch queue. So let the * completion_data share space with the rb_node. */ union { structrb_noderb_node;/* sort/lookup */ structbio_vecspecial_vec; void *completion_data; }; /* * completion callback. */ rq_end_io_fn *end_io; }
/** * struct blk_mq_hw_ctx - State for a hardware queue facing the hardware * block device */ structblk_mq_hw_ctx { /** * @queue: Pointer to the request queue that owns this hardware context. */ structrequest_queue *queue; /** * @dispatch_busy: Number used by blk_mq_update_dispatch_busy() to * decide if the hw_queue is busy using Exponential Weighted Moving * Average algorithm. */ unsignedint dispatch_busy; }
code flow in block layer
Bio -> Request -> plug request list -> staging request queue in sheduler -> hardware request queue


These pictures records the total main code and function flow from the filessystem to block layer and to driver layder. It also prints the tracepoint mapping to the acation in output of the blktrace where they trace from. By these tracepoint, we can understand the block io process flow more clearly.