ceph introduction
ceph相当庞大, 准备用一个系列来学习, 先来看看基础的架构和基本概念.
基本架构
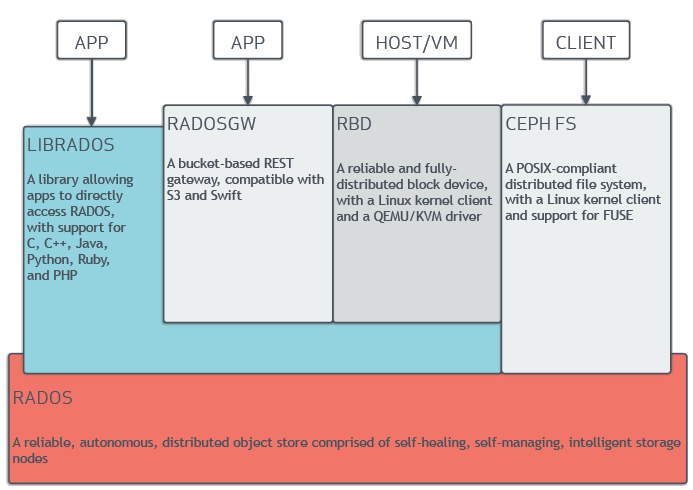
ceph提供对象, 块,和文件系统存储, 它也支持直接使用librados库做存储开发. 在底层都要通过RADOS服务, 它是可靠的分布式对象存储服务. 也就是说无论上层对外提供的是何种类型的服务, ceph最终都将它转换成二进制对象进行存储.
可扩展性和高可用性
一个ceph存储集群包括两种类型的Daemon:
- ceph monitor: 维护一个集群map的副本. ceph monitor是高可用的.
- ceph osd daemon: 检查自己的状态和其他osd的状态, 然后发送给monitor. ceph client和ceph osd daemon都使用CRUSH算法有效计算数据位置信息, 而不是依赖于一个中心化的查询表.
Ceph OSD Daemon将所有数据以对象的形式保存在一个扁平的命名空间(而不是树形结构). 一个对象有一个全局唯一的ID号, 二进制数据和元数据(key/value键值对组成). 对象的语意完全由ceph客户端决定.

ceph消除了中心化的gateway, 让Ceph client直接与ceph osd daemon交互, ceph osd daemon将数据在不同的ceph 节点 创建对象的副本, 保证数据的可用性.
集群map
monitor map: 包含集群fsid, 位置, 命名地址和每个monitor的端口. epoch表示版本, 通过ceph mon dump查看
1
2
3
4
5
6
7[root@ceph-1 ~]# ceph mon dump
dumped monmap epoch 1
epoch 1
fsid a6af0fa0-0e86-4685-920a-6e999c83ba8f
last_changed 2018-07-09 15:07:50.144554
created 2018-07-09 15:07:50.144554
0: 10.0.11.9:6789/0 mon.ceph-1OSD map: 包含集群fsid. a list of pools, replica sizes, PG numbers, a list of OSDs and their status (e.g.,
up,in).The PG map: 包含PG version, its time stamp, the last OSD map epoch, the full ratios, and details on each placement group such as the PG ID, the Up Set, the Acting Set, the state of the PG (e.g.,
active + clean), and data usage statistics for each poolThe CRUSH map: 存储设备列表, 失败的Domain, 已经写入数据的水平路由规则.
The MDS Map: Contains the current MDS map epoch, when the map was created, and the last time it changed
Ceph Crush
那么问题来了,把一份数据存到一群Server中分几步?
Ceph的答案是:两步。
- 计算PG
- 计算OSD
计算PG
在Ceph中,一切皆对象。
那么用什么来区分两个对象呢?对象名。也就是说,每个不同的对象都有不一样的对象名。于是,开篇的问题就变成了:
把一个对象存到一群Server中分几步?
这里的一群Server,由Ceph组织成一个集群,这个集群由若干的磁盘组成,也就是由若干的OSD组成。于是,继续简化问题:
把一个对象存到一堆OSD中分几步?
Ceph中的逻辑层
Ceph为了保存一个对象,对上构建了一个逻辑层,也就是池(pool),用于保存对象.
Pool再一次进行了细分,即将一个pool划分为若干的PG(归置组 Placement Group),这类似于棋盘上的方格,所有的方格构成了整个棋盘,也就是说所有的PG构成了一个pool。
现在需要解决的问题是,对象怎么知道要保存到哪个PG上,假定这里我们的pool名叫rbd,共有256个PG,给每个PG编个号分别叫做0x0, 0x1, ...0xF, 0x10, 0x11... 0xFE, 0xFF。
要解决这个问题,我们先看看我们拥有什么,1,不同的对象名。2,不同的PG编号。这里就可以引入Ceph的计算方法了 : HASH。
对于对象名分别为bar和foo的两个对象,对他们的对象名进行计算即:
- HASH(‘bar’) = 0x3E0A4162
- HASH(‘foo’) = 0x7FE391A0
- HASH(‘bar’) = 0x3E0A4162
对于一个同样的对象名,计算出来的结果永远都是一样的.
有了这个输出,我们使用小学就会的方法:求余数!用随机数除以PG的总数256,得到的余数一定会落在[0x0, 0xFF]之间,也就是这256个PG中的某一个:
- 0x3E0A4162 % 0xFF ===> 0x62
- 0x7FE391A0 % 0xFF ===> 0xA0
于是乎,对象bar保存到编号为0x62的PG中,对象foo保存到编号为0xA0的PG中。
所以每个对象自有名字开始,他们要保存到的PG就已经确定了。那么爱思考的小明同学就会提出一个问题,难道不管对象的高矮胖瘦都是一样的使用这种方法计算PG吗,答案是,YES! 也就是说Ceph不区分对象的真实大小内容以及任何形式的格式,只认对象名。毕竟当对象数达到百万级时,对象的分布从宏观上来看还是平均的。
这里给出更Ceph一点的说明,实际上在Ceph中,存在着多个pool,每个pool里面存在着若干的PG,如果两个pool里面的PG编号相同,Ceph怎么区分呢? 于是乎,Ceph对每个pool进行了编号,比如刚刚的rbd池,给予编号0,再建一个pool就给予编号1,那么在Ceph里,PG的实际编号是由pool_id+.+PG_id组成的,也就是说,刚刚的bar对象会保存在0.62这个PG里,foo这个对象会保存在0.A0这个PG里。其他池里的PG名称可能为1.12f, 2.aa1,10.aa1等。
Ceph中的物理层
理解了刚刚的逻辑层,我们再看一下Ceph里的物理层,对下,也就是我们若干的服务器上的磁盘,通常,Ceph将一个磁盘看作一个OSD(实际上,OSD是管理一个磁盘的程序),于是物理层由若干的OSD组成,我们的最终目标是将对象保存到磁盘上,在逻辑层里,对象是保存到PG里面的,那么现在的任务就是打通PG和OSD之间的隧道。PG相当于一堆余数相同的对象的组合,PG把这一部分对象打了个包,现在我们需要把很多的包平均的安放在各个OSD上,这就是CRUSH算法所要做的事情:CRUSH计算PG->OSD的映射关系。
加上刚刚的对象映射到PG的方法,我们将开篇的两步表示成如下的两个计算公式:
- 池ID + HASH(‘对象名’) % pg_num ===> PG_ID
- CRUSH(PG_ID) ===> OSD
在讨论CRUSH算法之前,我们来做一点思考,可以发现,上面两个计算公式有点类似,为何我们不把
CRUSH(PG_ID) ===> OSD
改为HASH(PG_ID) %OSD_num ===> OSD
我可以如下几个由此假设带来的副作用:
- 如果挂掉一个OSD,
OSD_num-1,于是所有的PG % OSD_num的余数都会变化,也就是说这个PG保存的磁盘发生了变化,对这最简单的解释就是,这个PG上的数据要从一个磁盘全部迁移到另一个磁盘上去,一个优秀的存储架构应当在磁盘损坏时使得数据迁移量降到最低,CRUSH可以做到。(这一点一致性哈希也能做到) - 如果保存多个副本,我们希望得到多个OSD结果的输出,HASH只能获得一个,但是CRUSH可以获得任意多个。
- 如果增加OSD的数量,OSD_num增大了,同样会导致PG在OSD之间的胡乱迁移,但是CRUSH可以保证数据向新增机器均匀的扩散。
所以HASH只适用于一对一的映射关系计算,并且两个映射组合(对象名和PG总数)不能变化,因此这里的假设不适用于PG->OSD的映射计算。因此,这里开始引入CRUSH算法。
CRUSH算法
首先来看我们要做什么:
- 把已有的PG_ID映射到OSD上,有了映射关系就可以把一个PG保存到一个磁盘上。
- 如果我们想保存三个副本,可以把一个PG映射到三个不同的OSD上,这三个OSD上保存着一模一样的PG内容。
再来看我们有了什么:
- 互不相同的PG_ID。
- 如果给OSD也编个号,那么就有了互不相同的OSD_ID。
- 每个OSD最大的不同的就是它们的容量,即4T还是800G的容量,我们将每个OSD的容量又称为OSD的权重(weight),规定4T权重为4,800G为0.8,也就是以T为单位的值。
现在问题转化为:如何将PG_ID映射到有各自权重的OSD上。这里我直接使用CRUSH里面采取的Straw算法,翻译过来就是抽签,说白了就是挑个最长的签,这里的签指的是OSD的权重。
- CRUSH_HASH( PG_ID, OSD_ID, r ) ===> draw
- ( draw &0xffff ) * osd_weight ===> osd_straw
- pick up high_osd_straw
第一行,我们姑且把r当做一个常数,第一行实际上就做了搓一搓的事情:将PG_ID, OSD_ID和r一起当做CRUSH_HASH的输入,求出一个十六进制输出,这和HASH(对象名)完全类似,只是多了两个输入。所以需要强调的是,对于相同的三个输入,计算得出的draw的值是一定相同的。
这个draw到底有啥用?其实,CRUSH希望得到一个随机数,也就是这里的draw,然后拿这个随机数去乘以OSD的权重,这样把随机数和OSD的权重搓在一起,就得到了每个OSD的实际签长,而且每个签都不一样长(极大概率),就很容易从中挑一个最长的。
说白了,CRUSH希望随机挑一个OSD出来,但是还要满足权重越大的OSD被挑中的概率越大,为了达到随机的目的,它在挑之前让每个OSD都拿着自己的权重乘以一个随机数,再取乘积最大的那个。那么这里我们再定个小目标:挑个一亿次!从宏观来看,同样是乘以一个随机数,在样本容量足够大之后,这个随机数对挑中的结果不再有影响,起决定性影响的是OSD的权重,也就是说,OSD的权重越大,宏观来看被挑中的概率越大。
如果看到这里你已经被搅晕了,那让我再简单梳理下PG选择一个OSD时做的事情:
- 给出一个PG_ID,作为CRUSH_HASH的输入。
- CRUSH_HASH(PG_ID, OSD_ID, r) 得出一个随机数(重点是随机数,不是HASH)。
- 对于所有的OSD用他们的权重乘以每个OSD_ID对应的随机数,得到乘积。
- 选出乘积最大的OSD。
- 这个PG就会保存到这个OSD上。
现在趁热打铁,解决一个PG映射到多个OSD的问题,还记得那个常量r吗?我们把r+1,再求一遍随机数,再去乘以每个OSD的权重,再去选出乘积最大的OSD,如果和之前的OSD编号不一样,那么就选中它,如果和之前的OSD编号一样的话,那么再把r+2,再次选一次,直到选出我们需要的三个不一样编号的OSD为止!
当然实际选择过程还要稍微复杂一点,我这里只是用最简单的方法来解释CRUSH在选择OSD的时候所做的事情。
基于这样的结构选择OSD,我们提出了新的要求:
- 一共选出三个OSD。
- 这三个OSD需要都位于一个row下面。
- 每个cabinet内至多有一个OSD。
这样的要求,如果用上一节的CRUSH选OSD的方法,不能满足二三两个要求,因为OSD的分布是随机的。